Data Science for Linguists 2021
Course home for
LING 1340/2340
HOME 
• Policies
• Term project guidelines
• Learning resources by topic
• Schedule table
Homework 4: Supercomputing the Yelp Dataset
This homework carries a total of 80 points.
In class, we switched to a more proper venue for the Yelp data: the CRC’s h2p supercomputer cluster. We already gave To-do #12 a supercomputing treatment. For this homework, we will take it one step further: machine learning. What does it take to unleash machine learning on “big data”? Let’s find out.
For this homework, in your home directory on CRC, create a folder called hw4_yelp/ and keep all your work in here. This will be your submission.
Plan of attack
Wrestling with big data can get hairy without some pre-planning. Separate your work into two stages:
- A TRIAL RUN on a tiny slice of data: 10,000 reviews
- The “FOO” principle still applies: start small. You don’t want to discover a bug in your script 30 minutes into a big job! In your
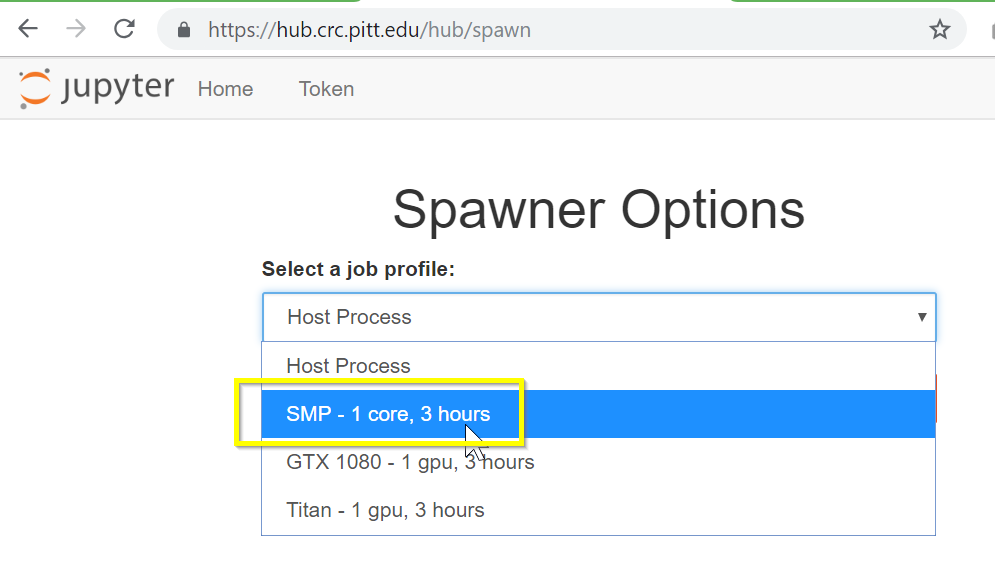
hw4_yelp/directory, create a file namedreview_10k.jsonas a mini version ofyelp_academic_dataset_review.json, containing only 10,000 lines, and work with it. - PLATFORM: Remote Jupyter Notebook through CRC’s JupyterHub. Make sure to choose SMP - 1 core, 3 hours when spawning!
- This is when you explore your data, experiment with your models, visualize: essentially the whole gamut of data-sciencing.
- The goal here is for you to find a good model and some parameters for a benchmark, and also to develop the code you will use will later use on a lot more data. The miniature data size and the Jupyter Notebook interface make this process far more manageable.
- To make Part 2 quicker, you should write your code here to make use of GridSearchCV and pipelines.
- That said, don’t go overboard with many different classifier models. You can even focus on a single classifier model with different parameters.
- The “FOO” principle still applies: start small. You don’t want to discover a bug in your script 30 minutes into a big job! In your
- A FULL(ish)-SCALE RUN
- This you don’t want to do through Jupyter Notebook! You will need a proper slurm job submission.
- PLATFORM therefore should be: Command-line python script through slurm job submission.
- Your Python script can be exported from your Jupyter Notebook:
- First, load appropriate python if you haven’t already:
module load python/3.7.0 - Then:
jupyter nbconvert --to script your_notebook.ipnyb. This producesyour_notebook.py.
- First, load appropriate python if you haven’t already:
- Streamline your script by removing code blocks that are mainly there for exploration. Visualization likewise is not useful here (unless you save out plots into a file).
- To begin, train and test just ONE parameter combination using
GridSearchCV. Basically this means passing in lists of length 1 for each of the parameters you’re trying to tune. - Once you’ve done that, you can try using the same model with a larger # of parameter combos, but make sure to take advantage of parallel processing. You should utilize the
n_jobsparameter inGridSearchCV(your python script), and the#SBATCH --cpus-per-task=nsetting (your Slurm script). You’ll notice that as you increase the number n things will run faster, but you will consume more memory (verify throughseff <job-id>). - If your job is getting killed because of time limit, add this line in your script:
#SBATCH --time=180which will give you 3 hours of runtime instead of the default 60. (Caveat: requesting a lager time block may result in a longer wait time in job queue.) But what if 3, 4, or even 5 hours aren’t enough? Before requesting even more, you should first look into options for decreasing time complexity of your code. - Still, the entire set of 8.6 million reviews is a LOT. We recommend you start with initial 1 or 2 million lines, and go up to 4 mil only after. Would be nice to successfully train/test with the entire set, but your best try is fine for this homework. You might find your jobs taking a few hours to run…
- If you are using full 8.6 million reviews (yay!), do NOT make a copy in your working directory. Instead, your script should read directly from the original file
/bgfs/ling2340_2021s/shared_data/yelp_dataset_2021/yelp_academic_dataset_review.json. - BTW, if you need to cancel your job, use:
scancel <job-id>.
{kind=link}
Task: Classifying negative vs. positive reviews
As for the task itself, we’ll keep it simple: negative vs. positive review classification. It’s essentially a binary classification problem and a type of sentiment analysis.
- Target labels should be ‘neg’ and ‘pos’. Details:
- Count 1- and 2- star reviews as negative. Likewise, treat 4- and 5- star reviews as positive.
- What about 3 stars? We’ll simply ignore them. You can drop these from your data.
- Specifics:
- In terms of features, try TF-IDF vectors and any other features you feel could be useful.
- Choose one kind of model to thoroughly test.
- You should build a Pipeline model.
- Use GridSearchCV and try various combinations of parameters for each model + perform 5-fold CV.
- Try to tune at least 1 parameter for each component of the pipeline you produce, and try at least 2 different values per parameter.
- For each set of parameters tested by your grid search, you should print out the configuration as well as the mean accuracy across all cross validation splits for that configuration.
Summary report as README.md
That’s a lot of moving parts and files, so create a summary document that rounds up everything plus a bit of further analysis. In your README.md file:
- List the content of your submission, that is, the files in your
hw4_yelp/directory. Give a very short description of the content/purpose. - Your “full(ish)-scale run” produced some numbers which will need interpretation and analysis. Do so here in its own separate section.
- A section on further analysis. Look closely at the documentation for the dataset. What are some other analysis questions you might be able to investigate with your machine learning skills? What else would you find interesting to predict, and which attributes might serve as useful features?
- Lastly, summarize the computing resource aspect of your work: data size, parallel jobs utilized, memory usage, wall-time, etc. Also, any thoughts on big data and supercomputing you might have.
Some things to keep in mind:
- Start early! Your slurm jobs will be stuck in a batch queue and and have to wait their turn to run. And when they start running, they’ll probably take a while. They might even crash halfway through running if you have mistakes in your code…
- If you need some additional python package, after loading the appropriate python module on CRC, run
pip install <package> --userto install a copy for yourself. If you need the package on https://hub.crc.pitt.edu, in a cell at the top of your notebook, run!pip install <package> --user. - The Yelp dataset as well as NLTK’s corpus and grammar data are all found in our shared data folder:
/bgfs/ling2340_2021s/shared_data/. - To run any NLTK function that relies on
nltk_data(e.g.,word_tokenize), you should executenltk.data.path.append('/bgfs/ling2340_2021s/shared_data/nltk_data')in your script. - Editor: If you’re using the command line to edit things, you’ll have to use
nano, which works fine for a quick edit. For more involved/extensive edits, you should use JupyterHub’s text editor. - Editor: Still, if you miss your favorite editor programs such as Atom and Notepad++, there is a way (of course). Many text editors have packages you can install that will open up a connection to the server and allow you to edit things from your local editor. For example, in Atom, from Edit > Preferences > Install, you can get the remote-edit package, which well let you input the information you need open up a connection with the CRC server.
Submission
We have read access to your hw4_yelp/ directory, so that’s your submission. It should include:
- README.md
- Slurm job files
- Output files
review_10k.jsonfilereview_Xmil.jsonfile(s)- Python script(s)
- Jupyter notebook(s)