Data Science for Linguists 2022
Course home for
LING 1340/2340
HOME 
• Policies
• Term project guidelines
• Learning resources by topic
• Schedule table
Daily To-do Assignments
To-do #1
Due 1/13 (Th), 3:45pm
The Internet is full of published linguistic data sets. Let’s data-surf! Instructions:
- Go out and find two linguistic data sets you like. One should be a corpus, the other should be some other format. They must be free and downloadable in full. Make sure they are linguistic data sets, meaning designed for linguistic inquiries.
- You might want to start with various bookmark sites listed in the following Learning Resources sections: Linguistic Data, Open Access, Data Publishing and Corpus Linguistics. But don’t be constrained by them.
- Download the data sets and poke around. Open up a file or two to take a peek. (No need to do this in Python: Save that for HW1.)
- In a text file (should have the
.txtextension), make note of:- The name of the data resource
- The author(s)
- The URL of the download page
- Its makeup: size, type of language, format, etc.
- License: whether it comes with one, and if so what kind?
- Anything else noteworthy about the data. A sentence or two will do.
- If you are comfortable with markdown, make an
.mdfile instead of a text file.
SUBMISSION: On Canvas. Upload your text file through the To-do1 submission link.
To-do #2
Due 1/20 (Th), 3:45pm
Learn about the numpy library: study the Python Data Science Handbook and/or the DataCamp tutorial.
While doing so, create your own study notes, as a Jupyter Notebook file entitled numpy_notes_yourname.ipynb.
Include examples, explanations, etc. Replicating DataCamp’s examples is also something you could do.
You are essentially creating your own reference material.
SUBMISSION: Your file should be in the todo2/ directory of the Class-Exercise-Repo.
Make sure it’s configured for the “upstream” remote and your fork is up-to-date. Push to your GitHub fork, and create a pull request for me.
To-do #3
Due 1/25 (Tue)
Study the pandas library (through the Python Data Science Handbook and/or the DataCamp tutorials). pandas is a big topic with lots to learn: aim for about 1/2. While doing so, try it out on TWO spreadsheet (.csv, .tsv, etc.) files:
- The first file should be your choice. You can get one from this CSV Files archive, or make up your own. Keep it super small and simple at 5-100 rows. This is supposed to be a toy dataset that helps you learn!
- The second one should be
billboard_lyrics_1964-2015.csvby Kaylin Pavlik, from her project ‘50 Years of Pop Music’. (Note: you might need to specify ISO8859 encoding when opening.)
Don’t change the filename of any downloaded CSV files or edit them in any way – important! Name your Jupyter Notebook file pandas_notes_yourname.ipynb.
SUBMISSION: Your files should be in the todo3/ directory of Class-Exercise-Repo.
Commit and push all three files to your GitHub fork, and create a pull request for me.
To-do #4
Due 1/27 (Thu)
This one is a continuation of To-do #3: work further on your pandas study notes. You may create a new JNB file, or you can expand the existing one. Also: try out a spreadsheet submitted by a classmate. You are welcome to view the classmate’s notebook to see what they did with it. (How to find out who submitted what? Git/GitHub history of course.) Give them a shout-out.
SUBMISSION: We’ll stick to the todo3/ directory in Class-Exercise-Repo. Push to your GitHub fork, and create a pull request for me.
To-do #5
Due 2/10 (Thu), earlier at 2pm!!
Let’s dig into the issues of copyright and license in language data. We’ll then pool our questions together for Dr. Lauren Collister.
Review the topics of linguistic data, open access, and data publishing, focusing in particular on her 2022 article for the Open Handbook of Linguistic Data Management and the “Copyright and Intellectual Property Toolkit”. Then watch her guest presentation from last year; her slides can be found here.
Think of a question or two on the topic, and add yours along with your name to this Word document posted on our MS Teams forum. Dr. Collister will join our class on Thursday to answer them.
SUBMISSION: The shared MS Word document is your submission.
To-do #6
Due 2/17 (Thu)
Let’s try Twitter mining! On a tiny scale that is. Step-by-step tutorials are posted in this Resources section, so pick one and follow along. Take a look at my in-class demo too: I used the older Twitter API protocol v1.1, but try and see if you can use the latest v2.
Before beginning, you will need to install the tweepy library. If you are using Anaconda python, you can do so via Anaconda Navigator’s “Environments” tab. If you have python.org’s python, you should use pip in command line.
Notes on using tweepy:
- If you don’t have a Twitter account, you will have to create one first. And then, you should create an API account.
- This is exciting stuff, but don’t go overboard! 100 Tweets are enough for this exercise. Overloading API without taking proper cautionary steps is a sure-fire way to get yourself banned from tech sites.
- You will be using your ‘Consumer Key’ and ‘Consumer Secret’ in your code. You should not be sharing them! Before adding the file in
git, redact them in your JNB file by changing the string values to ‘XXXXXXXXXXXXXX’.
SUBMISSION: We will use Class-Exercise-Repo, the todo6/ folder. Your Jupyter Notebook file should have your name in the file name. Push to your fork and create a pull request. Make sure you have redacted your personal API keys!
To-do #7
Due 2/22 (Tue)
Let’s try our hands on annotation! Head to this URL to access Na-Rae’s WebAnno annotation server. Log in with your user ID (same as your Pitt ID) and password (first 4 digits of your Peoplesoft number).
You will see two documents: Japanese.txt is for part-of-speech annotation, and covid.txt is for named entity annotation.
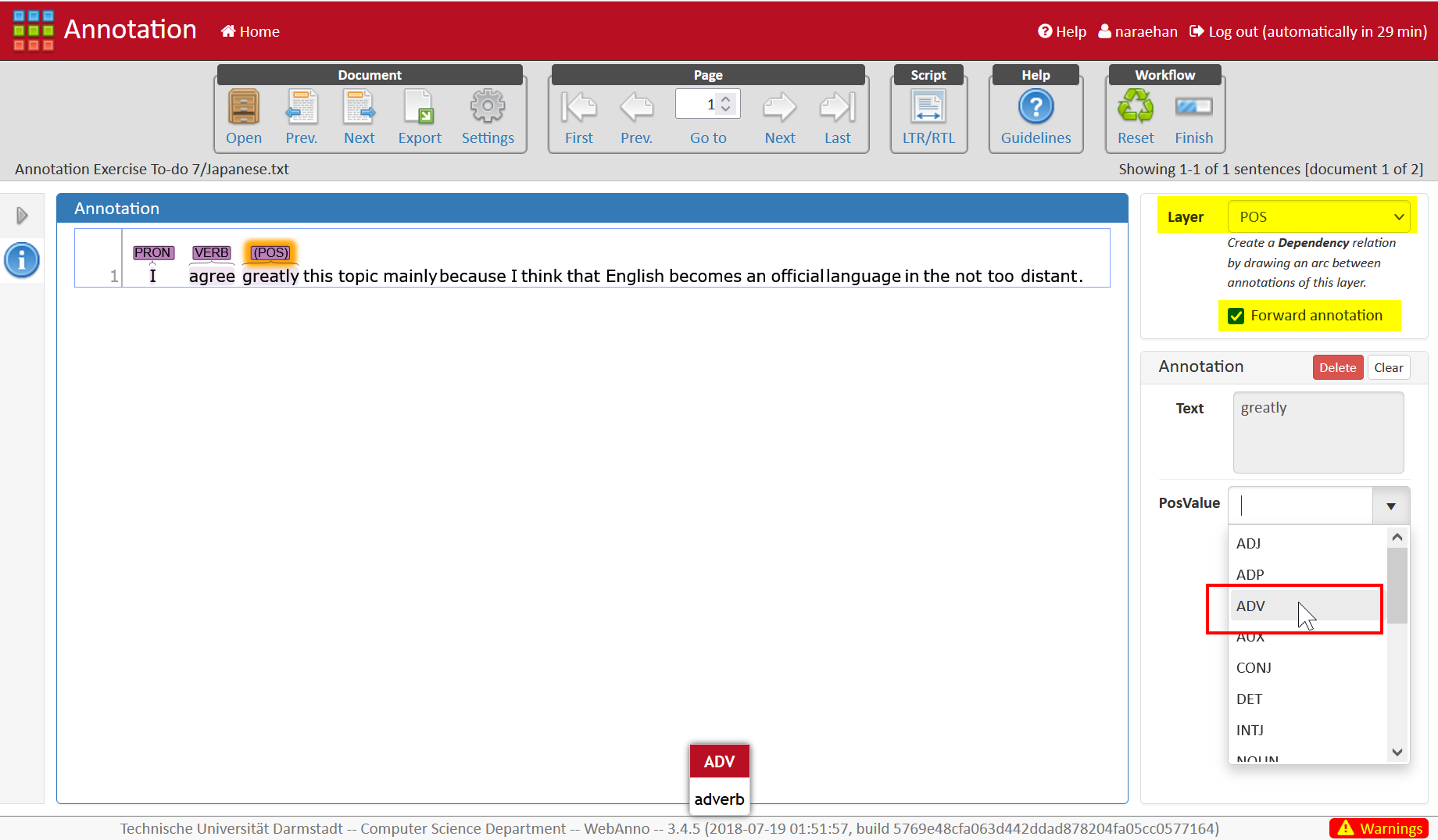
- Part-of-speech (
Japanese.txt)- We are using the Universal POS tagset by the Universal Dependencies project. You can learn more about the tags on their page.
- This annotation is done per word token. Make sure to select the POS layer, and also check “Forward annotation” box. See this screenshot.
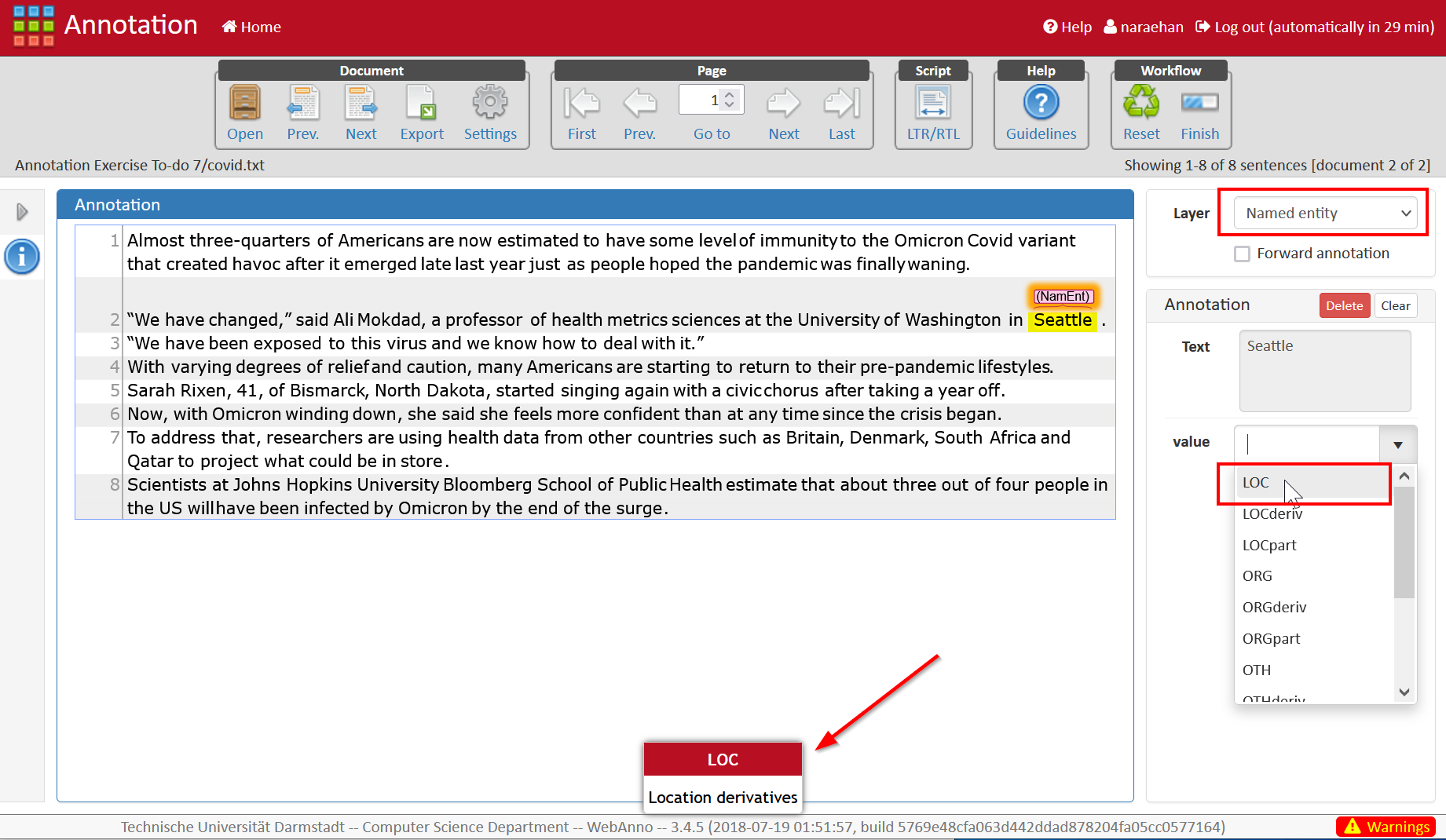
- Named Entity (
covid.txt)- Here, focus on four tags: LOC (location), ORG (organization), PER (person), and OTH (other). See this screenshot.
- By default, the app will show you only the first 5 sentences; to see all 8, change your setting following this screenshot.
{kind=link}
{kind=link}
{kind=link}
Without learning all the details about the annotation guidelines, try your best. This is just getting our hands on the process. The point of this To-do is for us to aggregate everyone’s annotation and see what the process is like from the annotation manager’s point of view. You are also welcome to try out any annotation layer you want.
SUBMISSION Your annotation itself is submission!
To-do #8
Due 3/1 (Tue)
Let’s try sentiment analysis on movie reviews. Follow this tutorial in your own Jupyter Notebook file. Feel free to explore and make changes as you see fit. If you haven’t already, review the Python Data Science Handbook chapters to give yourself a good grounding. Also: watch DataCamp tutorials Supervised Learning with scikit-learn, and NLP Fundamentals in Python.
Students who took LING 1330 (=everyone): compare sklearn’s Naive Bayes with NLTK’s treatment and include a blurb on your impression. (You don’t have to run NLTK’s code, unless you want to!)
SUBMISSION: Your jupyter notebook file should be in the todo8 folder of Class-Exercise-Repo. As usual, push to your fork and create a pull request.
To-do #9
Due 3/3 (Thu)
What have the previous students of LING 1340/2340 accomplished? What do finished projects look like? Let’s have you explore their past projects. Details:
- GitHub wise, we’ll brave a new frontier: editing shared files! To minimize potential conflicts and clean up efforts, I am breaking you into two teams: Team A and Team B. Find your name in there.
- Pick from three previous years: 2021 spring, 2020 spring, and 2019 spring.
- Pick two projects, but you can’t pick one that already has two critiques. (If someone gets the last spot while you’re working, you’ll have to pick a new one. And: declaring “dips” is allowed, as long as you intend to finish the work within the next hour.)
- Provide links to the project repos. It’s a must!
- Your critique should consist of: (1) one thing you thought was done well, (2) one avenue for improvement, and (3) one thing you learned.
- As you pull from upstream, your file may end up being in conflict. It’s your job to edit the markdown file and get it to a tidy state before your submission. Be careful not to trample on your classmate’s work! You can learn about how to resolve conflicts here.
SUBMISSION: As usual, push to your fork and create a pull request. Make sure your team’s markdown file is in good shape!
To-do #10
Due 3/17 (Thu)
What has everyone been up to? Let’s take a look – it’s a “visit your classmates” day!
- First off, prepare your own “Guestbook” file. It’s already been created in the
Class-Loungerepo, but you should edit it so that:- It has your project title and a link to your repo, and your name
- And a bit of personalization if you want, like a greeting.
- Now visit your classmates’ projects! We will go by the order of first names, which can be found right in the directory. You should visit two people after you (Abby: Emily and Emma, Michael: Sonia and Abby, etc.)
- Take a look around, and write on their guestbook. (You don’t have to wait until it’s prepped.) Like the previous To-do, your entry should consist of: one thing you thought was done well, one avenue for improvement or suggestion, and one thing you learned.
SUBMISSION: Since Class-Lounge is a fully collaborative repo, there is no formal submission process.
To-do #11
Due 3/22 (Tue)
Visit your classmates, round 2.
- First, maintain your own guestbook. Respond to your classmates’ visit logs.
- No need to post a lengthy response – you are not starting a debate here! You can think of it as something akin to Facebook’s “like”, just a small acknowledgment or a thank you.
- Now visit your classmates’ projects, two of ‘em. Like before we go by the order of first names, which can be found right in the directory. You should visit two people after your previous visits.
- Take a look around, and write on their guestbook. Like the previous visit, your entry should consist of: one thing you thought was done well, one avenue for improvement or suggestion, and one thing you learned.
SUBMISSION: Since Class-Lounge is a fully collaborative repo, there is no formal submission process.
To-do #12
Due 3/29 (Tue)
Let’s poke at big data. Well, big-ish – how about 8.6 million restaurant reviews? The Yelp DataSet Challenge has been going strong for 10+ years now, where Yelp make their huge review dataset available for academic groups that participate in a data mining competition. Challenge accepted! Before we begin:
- You will need a strong and stable internet connection and at least 16GB of free disk storage space.
- Provision enough time. Downloading the dataset alone may take 25 minutes or longer.
- If your laptop is fairly old or running out of space, consider using Pitt’s campus lab. Windows users: Git Bash is not installed on Pitt’s campus lab machines and you likely can’t install it yourself, but you can download and use a portable version of Git Bash.
Mode of operation
- After downloading the data set, you should operate exclusively in a command-line environment, utilizing unix tools.
- I am supplying general instructions below, but you will have to fill in the blanks between steps, such as cd-ing into the right directory, invoking your Anaconda Python and finding the right file argument.
Step 1: Preparation, exploration
Let’s download this beast and poke around.
- Download the JSON portion of the data. (We don’t need the photos.)
- Move the downloaded archive file into your
Documents/Data_Sciencedirectory. You might want to create a new folder there for the data files. - From this point on, operate exclusively in command line.
- The file is in the
.tarformat. Look it up if you are not familiar. Untar it usingtar -xvf. I will extract 5 json files along with a PDF document. - Using various unix commands (
ls -laFh,head,tail,wc -l, etc.), find out: how big are the json files? What do the contents look like? How many reviews are there? - How many reviews use the word ‘horrible’? Find out through
grepandwc -l. Take a look at the first few throughhead | less. Do they seem to have high or low stars? - How many reviews use the word ‘scrumptious’? Do they seem to have high stars this time?
Step 2: A stab at processing
How much processing can our own puny personal computer handle? Let’s find out.
- First, take stock of your computer hardware: disk space, memory, processor, and how old it is.
- Create a Python script file:
process_reviews.py. Content below. You can use nano, or you could use your favorite editor (atom, notepad++) provided that you launch the application through command line.
import pandas as pd
import sys
from collections import Counter
filename = sys.argv[1]
df = pd.read_json(filename, lines=True, encoding='utf-8')
print(df.head(5))
wtoks = ' '.join(df['text']).split()
wfreq = Counter(wtoks)
print(wfreq.most_common(20))
- We are NOT going to run this on the whole
review.jsonfile! Start small by creating a tiny version consisting of the first 10 lines, namedFOO.json, usingheadand>. - Then, run
process_reviews.pyonFOO.json. Note that the json file should be supplied as command-line argument to the Python script, so your command will look something like below.python process_reviews.py FOO.json
- Confirm it ran successfully.
- Next, re-create
FOO.jsonwith incrementally larger total # of lines and re-run the Python script. The point is to find out how much data your system can reasonably handle. Could that be 1,000 lines? 100,000? - While running this experiment, closely monitor the process on your machine. Windows users should use Task Manager, and Mac users should use Activity Monitor.
- Finally, write up a short summary on this shared markdown file in
Class-Lounge. A few sentences will do. How was your laptop’s handling of this data set? What sorts of resources would it take to successfully process it in its entirety and through more computationally demanding processes? Any other observations?
SUBMISSION: Your entry on this shared MD file. Make sure to properly resolve conflicts (if any)!
To-do #13
Due 3/31 (Thu)
Trying out CRC, with bigger data + better code!
Warm-up
- Following the H2P user guide, log into your CRC account.
- Try out the To-do #12 redux I demonstrated in class, using 1 million review data.
Take 1: Bigger data
- Let’s go bigger! Reprise the experiment using 4 million reviews this time.
- Files involved:
review_4mil.json(newly created),process_reviews.py(same Python script),todo13.sh(new slurm script),todo13.out(newly generated output file). - After the job is done, study the job stats via
seff job-idcommand.
Take 2: Better code
- Let’s improve our Python code this time. Create a new script file
process_reviews_eff.pywith the following. The code produces the same results, but structured differently.
import pandas as pd
import sys
from collections import Counter
filename = sys.argv[1]
df_chunks = pd.read_json(filename, chunksize=10000, lines=True, encoding='utf-8')
wfreq = Counter()
for chunk in df_chunks:
for text in chunk['text']:
wfreq.update(text.split())
print(wfreq.most_common(20))
- Keep the data size the same: 4 million reviews.
- Edit
todo13.shto run this new script. - After the job is done, study the job stats via
seff job-idcommand. Night and day! What about this new Python code led to this much improvement in efficiency? Give it some thought, we’ll discuss in class.
Take 3: EVEN BIGGER data and better code (optional, ONLY IF you’re curious!)
- Run the new, improved Python script on all of review data, which consists of 8.6 million reviews total.
- When the job is done, again check the stats. How long did it take to run, and how much RAM did the process use?
SUBMISSION: Your files on CRC are your submission. I have read access to them.
To-do #14
Due 4/7 (Thu)
Another round of “visit your classmates”. You know what to do!
To-do #15
Due 4/14 (Thu)
4th and final round of “visit your classmates”, also the last To-do! Visit the two remaining classmates.